Large capacity SSDs (i.e., 30TB+) bring a new set of challenges. The two most relevant are:
- Large capacity SSDs are enabled by high density NAND, like QLC (quad-level cell NAND that stores 4 bits of data per cell), which brings more challenges compared to TLC NAND (triple-level cell, storing 3 bits per cell).
- SSD capacity growth commands an equivalent growth of local DRAM memory for maps that have traditionally been a ratio of 1:1000 (DRAM to Storage Capacity).
Currently, we are at a point where the ratio of 1:1000 is no longer sustainable. But do we really need it? Why not a ratio of 1:4000? Or 1:8000? They would reduce DRAM demand by a factor of 4 or 8 respectively. What prevents us from doing this?
This blog explores the thought process behind this approach, and tries to map a way forward for large capacity SSDs.
Firstly, why does DRAM need to be in a 1:1000 ratio with NAND capacity? The SSD needs to map the logical block addresses (LBA) coming from the system to NAND pages and needs to keep a live copy of all of them so it knows where data can be written to or read back. LBA size is 4KB and the map address is generally 32 bit (4 bytes), so we need one entry of 4 bytes every LBA of 4KB; hence the 1:1000 ratio. Note that very large capacities would need a bit more than this but, for simplicity, we’ll stick to this ratio as it makes the reasoning simpler and won’t materially change the outcome.
Having one map entry for each LBA is the most effective granularity as it allows the system to write (i.e., create a map entry) at the lowest possible granularity. This is often benchmarked with 4KB random writes, which is commonly used to measure and compare SSD write performance and endurance.
However, this may not be tenable in the long term. Instead, what if we had one map entry every 4 LBAs? or 8, 16, 32+ LBAs? If we use one map entry every 4 LBAs (i.e., one entry every 16KB) we may save DRAM size, but what happens when the system wants to write 4KB? Given the entry is every 16KB, the SSD will need to read the 16KB page, modify the 4KB that are going to be written, and write back the entire 16KB page. This would impact performance (“read 16KB, modify 4KB, write back 4KB”, rather than just “write 4KB”) but, most of all, this would impact endurance (system writes 4KB but SSD will end up writing 16KB to NAND) thus reducing the SSD life by a factor of 4. It is worrisome when this happens on QLC technology that has a much more challenging endurance profile. For QLC, if there is one thing that cannot be wasted it is endurance!
So, common reasoning is that the map granularity (or Indirection Unit – “IU” - in a more formal term) cannot be changed otherwise SSD life (endurance) would severely decline.
While all the above is true, do systems really write data at 4KB granularity? And how often? One can for sure buy a system just to run FIO with 4KB RW profile but realistically, people don’t use systems this way. They buy them to run applications, databases, file systems, object stores, etc. Do any of them use 4KB Writes?
We decided to measure it. We picked a set of various application benchmarks, from TPC-H (data analytics) to YCSB (cloud operations), running on various databases (Microsoft® SQL Server®, RocksDB, Apache Cassandra®), various File Systems (EXT4, XFS) and, in some cases, entire software defined storage solutions like Red Hat® Ceph® Storage, and measured how many 4KB writes are issued and what contribution they give to Write Amplification, i.e., extra writes that dent device life.
Before going into the details of the analysis we need to discuss why write size matters when endurance is at stake.
A 4KB write will create a “write 16K to modify 4K” and thus a 4x Write Amplification Factor (“WAF”). But what if we get an 8K write? Assuming that is inside the same IU, it will be a “write 16K to modify 8K” so WAF=2. A bit better. And if we write 16K? It may not contribute to WAF at all as one “writes 16K to modify 16KB”. So, only small writes contribute to WAF.
There is also a subtle case where writes may not be aligned, so there is always a misalignment that contributes to WAF but that also decreases rapidly with size.
The chart below shows this trend:
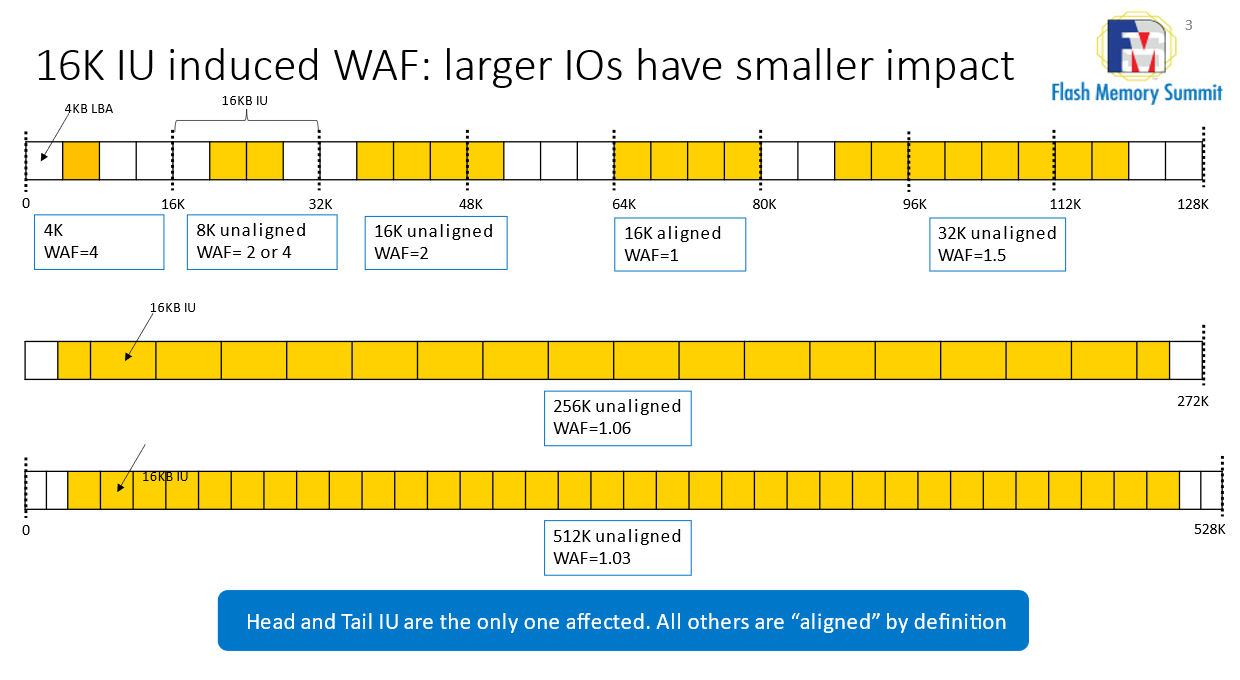 Luca Blog IU Figure 1: 16K IU induced WAF showing larger IOs have a smaller impact
Luca Blog IU Figure 1: 16K IU induced WAF showing larger IOs have a smaller impact
Large writes have minimal WAF impact. 256KB, for example, may have no impact (WAF=1x) if aligned, or minimal one (WAF=1.06x) if misaligned. Way better than the dreaded 4x coming from 4KB writes!
We then need to profile all writes coming to the SSD and look for their alignment within an IU to compute WAF contribution of each of them. And the larger the better. To do this, we instrumented the system to trace IOs for several benchmarks. We get samples for 20 min (generally between 100 and 300 million samples each benchmark) and then we post-process them to look at size, IU alignment, and add every single IO contribution to WAF.
The below table shows how many IOs fit in each size bucket:
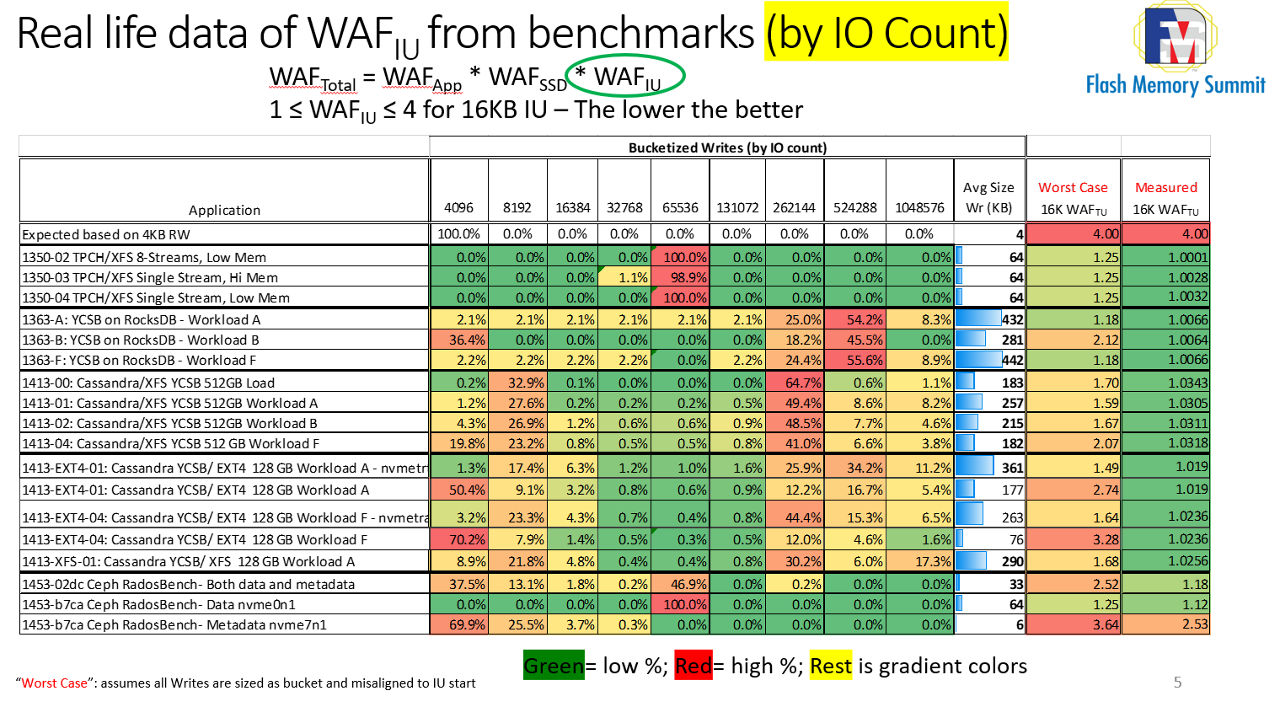 Luca Blog IU Figure 2: Real life data of WAF IU from benchmarks (by IO count)
Luca Blog IU Figure 2: Real life data of WAF IU from benchmarks (by IO count)
As shown, most writes either fit in the small size of 4-8KB (bad) bucket or in the 256KB+ (good) buckets.
If we apply the above WAF chart assuming all such IOs are misaligned, we get what is reported in “Worst case” column: most WAF is in the 1.x range, a few in the 2.x and very exceptionally in the 3.x range. Way better that expected 4x but not as good to make it viable.
However, not all IOs are misaligned. Why would they be? Why would a modern file system create structures that are misaligned to such small granularities? Answer: They don’t.
We measured each of the 100+ million IOs for each benchmark and post-processed them to determine how they align with a 16KB IU. The result is in the last column “Measured” WAF. It is generally less than 5%, i.e., WAF >=1.05x which means that one can grow the IU size by 400%, make large SSD using QLC NAND and existing, smaller DRAM technologies at a life cost that is >5% and not 400% as postulated! These are astonishing results.
One may argue “there are a lot of small writes at 4KB and 8KB and they do have a 400% or 200% individual WAF contribution. Shouldn’t the aggregated WAF be much higher because of such small but numerous IOs contributions?”. True, they are many, but they are small, so they carry a small payload and their impact, in terms of volume, is minimized. In the above table, a 4KB write counts as a single write as does a single 256KB write – but the latter carries 64x the amount of data than the former.
If we adjust the above table accounting for the IO Volume (i.e., accounting for each IO size and data moved), not by IO count, we come to the following representation:
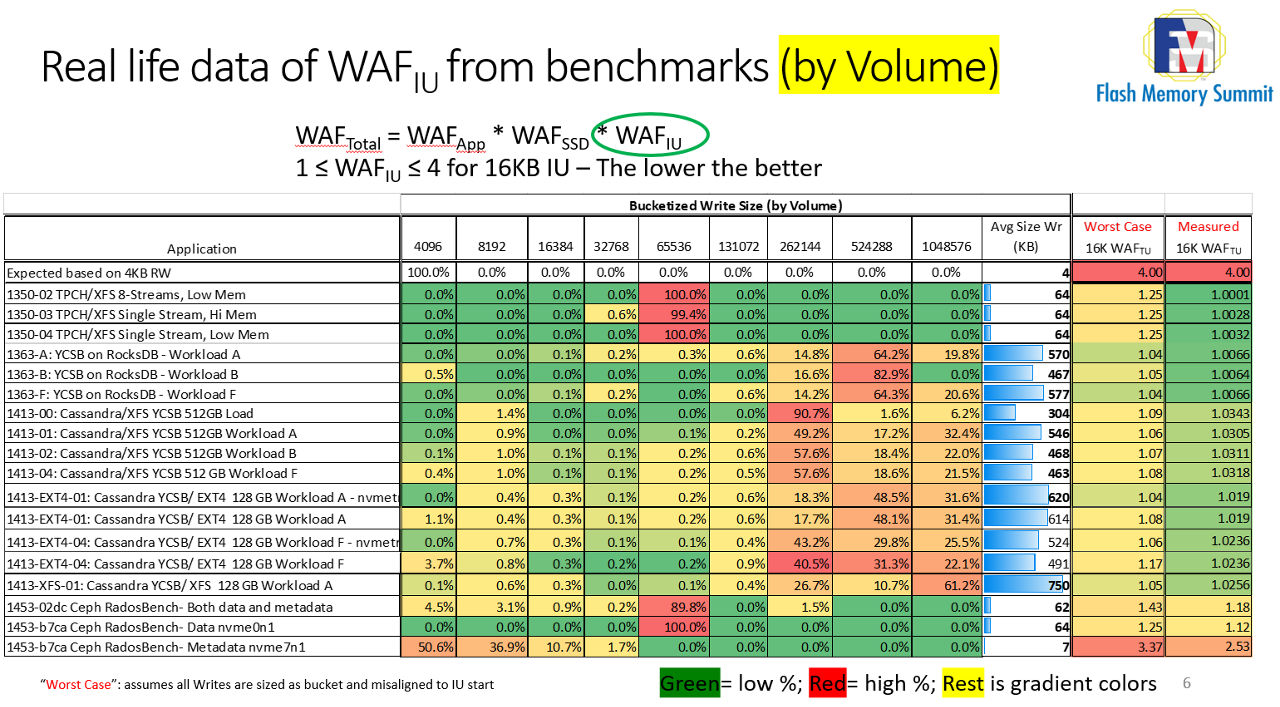 Luca Blog IU Figure 3: Real life data of WAF IU from benchmarks (by Volume)
Luca Blog IU Figure 3: Real life data of WAF IU from benchmarks (by Volume)
As we can see, the color grading for more intense IOs is now skewed to the right, meaning large IOs are moving an overwhelming amount of data and hence the WAF contribution is small.
One last thing to note is that not all SSD workloads are suitable for this approach. The last line, for example, represents the metadata portion of a Ceph storage node which does very small IO, causing high WAF=2.35x. Large IU drives are not suitable for metadata alone. However, if we mixed data and metadata in Ceph (a common approach with NVMe SSDs) the size and amount of data trumps the size and amount of metadata so the combined WAF is minimally affected.
Our testing shows that in actual apps and most common benchmarks, moving to 16K IU is a valid approach. The next step is convincing the industry to stop benchmarking SSDs with 4K RW with FIO which has bever been realistic and, at this point, is detrimental to evolution.
Impact of Different IU sizes
One of the most obvious follow up question is: why 16KB IU size? Why not 32KB or 64KB, does it even matter?
This is a very fair question that requires specific investigation and should be turned into a more specific question: what is the impact of different IU sizes for any given benchmark?
Since we already have traces that are unaffected by the IU size, we just have to run them through the appropriate model and see the impact.
Figure 4 shows the impact of IU sizes to WAF:
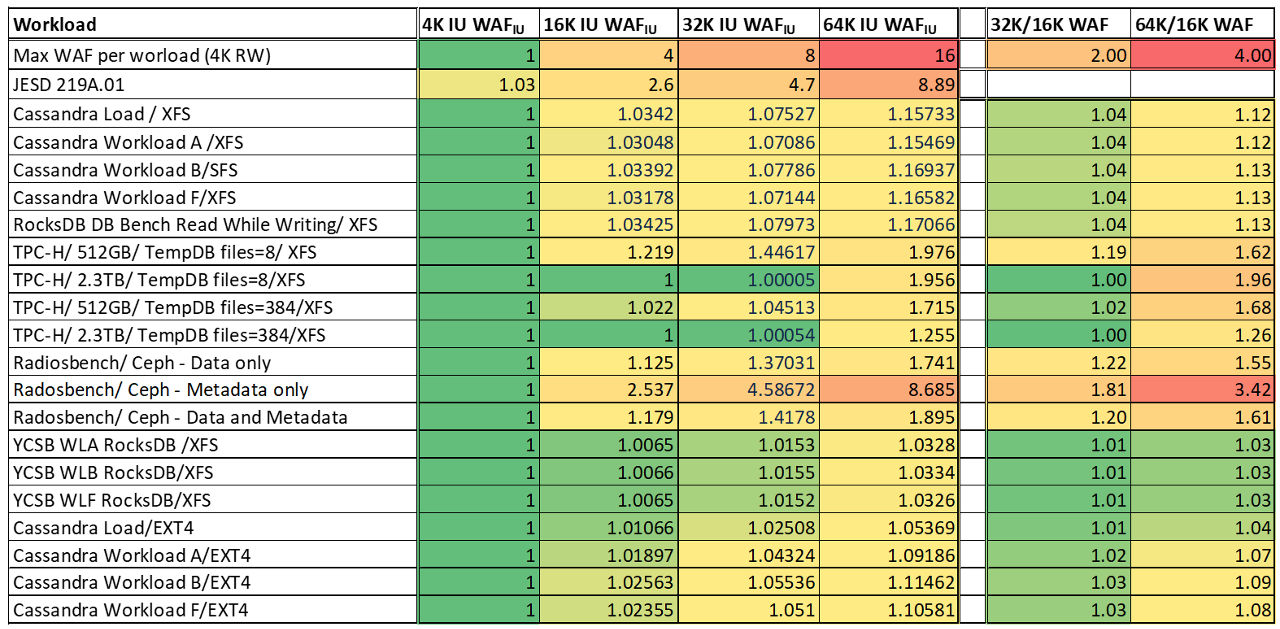 Luca Blog IU Figure 4: Impact of IU sizes to WAF
Luca Blog IU Figure 4: Impact of IU sizes to WAF
There are a few outcomes that can be evinced from the chart:
- IU size matters and WAF degrades with IU size. There is no good or bad solution, everybody has to look to the different tradeoffs based on its needs and targets.
- The WAF degradation is not nearly as bad as what may be feared, as in many cases we have seen above. Even in the worst case of 64KB IU and most aggressive benchmark, it is less than 2x as opposed to a feared 16x
- Metadata, as seen before, is always a bad pick for large IU and the larger the IU, the worse it becomes.
- JESD 219A, an industry standard profile to benchmarks WAF, is not good but acceptable at 4KB IU with an extra 3% WAF which is generally tolerable but becomes unusual at larger IU with a case point at 64K IU of almost 9x